Security Analyst Skills - Pt. 1 - Investigating Domains With URLScan
Does This Look Infected?
A lot of folks are interested in getting started in security (Infosec) and aren’t sure how to spend study time. Some do what I did for a few years and just read every security related thing they can come across. Not a bad thing to do if you ask me. Though much of it was advice to CISOs and policy stuff, as well as best practices (A LOT of best practices), this has been very useful to me when it comes to helping folks figure out what to be scared of and why.
99% of security posts I see on the web are devoted to ‘red teaming’/hacking stuff or how to secure your systems. Most folks start out in a 'blue team' or defense role as an analyst rather than offense as a penetration tester since these tend to be the most junior and most plentiful positions. Over this blog series, I’ll try to teach you the main analyst skills, methods, and kinds of thinking you’ll need. The goal is that when you finish this blog series, you'll know all the basics I picked up on the job - everything you need to nail an interview on a SOC or security operations team. This post is going to be about how to recognize dangers or indications something is wrong, which is a ‘blue team’/defender skill. (They are NOT mutually exclusive roles BTW.)
Let’s say you're working as a network admin, IT tech, etc., looking at a log of DNS requests (perhaps with a DNS solution like Cisco Umbrella, maybe a firewall, a SIEM (security GUI that accepts logs from things like firewalls and Windows Domain Controllers to draw out, correlate, categorize, and alert about events). Often you will come across an alert for one domain that the tool says is suspicious/possibly dangerous.
Lots of times you don’t get an entire URL to easily determine whether what is hosted there is malicious and you only have the domain. Other times, you simply see that there is traffic over port 443 or port 80 to a domain. (Sometimes malicious traffic pretends to be web traffic by using those typical HTTP/HTTPS ports.) How do you tell whether it represents a threat to your organization? There are reputation services that can do a pretty good job of helping you figure it out. Unfortunately sometimes they don’t have enough info, sometimes their info seems too old, etc.
The name of the game is confidence. Don't spend too much time, but gather enough data to give you a reasonable degree of confidence about whether you're dealing with a real threat or a false positive. You want to use multiple sources of data to make your decision. As I was taught, aim to be about 80% sure of your decision. You won't catch everything for various reasons, so "Do Your Best but Don't Obsess™." HOWEVER, do ask yourself if you performed all due diligence before issuing your decision.
(Ex.: You might've decided a site seems safe enough from looking at tools, but did you visit the site (safely, from a VM or hybrid-analysis.com?)
For this article we’ll pull an example from URLScan (https://urlscan.io). I’ll try to walk you through my thought process as we find out what we can learn about the domain. I chose this domain at random based on the fact that the name simply looks like something potentially malicious, and I have no prior knowledge of it before writing this article.
https://urlscan.io/result/a397e8e8-3947-443f-ad5d-bb0be34ea904/
(Those brackets around the dot? That is a typical way to avoid having a link auto-created when typing or pasting the URL and to reduce the chance someone you send it to accidentally clicks on a malicious link. Try to always do this even if you think nobody will click it.)
Looking at the screenshot of the domain, it doesn’t seem to be malicious, however I have a concern already:
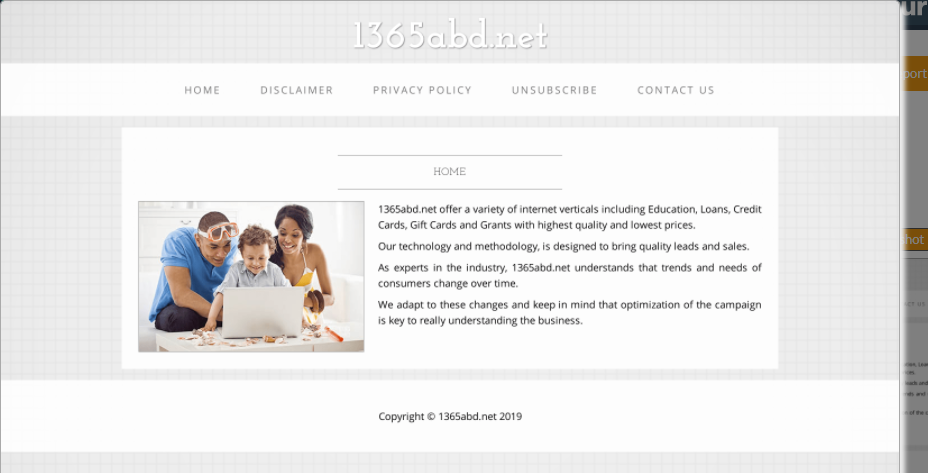
The site is clearly a blank template. Much like the WordPress templates. At this point I would consider it slightly more of a risk than if the page were blank or ‘Access Denied’ or ‘Not Found.’ I say this because if it were blank or just non functioning, nothing necessarily suspicious is implied.
Since this domain's front page has nothing but a template, the chances that this is a long forgotten, unused web space on some server go WAY up. If that's true, it's probably totally outdated, which means that it's a matter of time before some automated scanner notices and drops malware on it of some kind. Then a human user might take control for nefarious purposes. It’s also possible that an attacker threw this page up so that at a quick glance it looks normal.
Remember that we want avoid using of the information/facts we're hunting down here as a cause for judgement one way or the other alone, but instead to consider overall how likely it seems that this is related to some malicious situation. We need to build context and think about things like likely scenarios vs. unlikely scenarios.
As they say in the medical field, "if you hear hoofbeats, think horses, not zebras."
Let’s continue…
If we click “SHOW SCANS,” we can see every time someone submitted this domain for scanning in the past. This shows us:
Roughly how long ago it became active
Has this site been inactive for a long time as described a moment ago? Might be riddled with malware.
This domain’s first scan here was from about a month ago (Dec 2020). Fairly new. No concern yet. Of course, the domain could’ve sat much longer and was only used when compromised recently. There are ways to consider that too!
How can we find out when the domain was registered? When it was renewed? Has it been used for anything before then? If nobody scanned Google here, it would never show up.
URL’s which redirected visitors to this domain
If there’s a form of some kind at one of the URLs, is it likely innocent? Or did someone generate a link that sounds like it’s from an official agency then have it point here to collect data from a victim?
It would appear that most of these aren’t from redirects, but some are. Let’s examine the redirect entries:
over[.]st/45q
da[.]gd/eFcRJH
storage[.]googleapis[.]com/sdffsdfsd/unsbserv.html
uoo[.]lk/oU7fu
era[.]li/LTXR7U
The ‘redirected from’ URLs are all different domains. Looks like URL shortening, but normally one would tend to use the same shortening service (eg.: bit.ly) for all their legitimate operations. Instead these could be dynamically generated domains.
Notice the ‘googleapis.com’ domain. This is a handy way to have your malicious operations come from a Google Owned IP and domain so that folks consider it instantly legitimate. A lot of times it hosts user-generated content on Google servers. Google can’t know what all users might use that space for or if any given user’s web space has been compromised if the attackers can avoid attracting too much attention.
URL’s seen for this domain
Particularly useful when you don’t know what URL your user might’ve visited. We want to know what kind of activity caused the DNS request and if it was dangerous. Maybe you see that the domain hosts some phishing pages AND some legitimate pages. One poses a threat if visited, one may not.
Looks like the URLs submitted for this domain are very nearly all the same. This is very good news as it increases the chance that we might be able to put together a scenario that explains what might’ve happened leading to this appearing in the log/alert.
This oldest visit shows a screenshot with nothing but a form asking for an e-mail address to unsubscribe.
Could this simply be a way to harvest people’s e-mail addresses for spam purposes?
While investigating, bear in mind that the URL for a form being ‘googleapis.com’ is very suspicious if the form represents a large organization. They would use their own domain 99% of the time. A small business however, might do this. This is a question to remember if we find that the domain/owner/etc purports to be from a large company. (Merrill Lynch, Microsoft, Etc.)
-Using What We Found-
As we continue, constantly you should be considering what you might be able to find with a web search (usually Google) of what you have at that point. Not everything makes a great search item, but here’s how you can think about it:
“storage[.]googleapis[.]com/sdffsdfsd/unsbserv.html”
(remember that quotes " mean 'search this exactly')
I don't expect to find much (remember to remove the [ around the dots) because something like ‘sdffsdfsd’ in a URL is very likely dynamically generated. We have only one example of a URL that looks like this for our domain so far. We can’t tell whether this (sdffsdfsd) section changes with other URLs for the same purpose on this domain or not.
Ready to search:
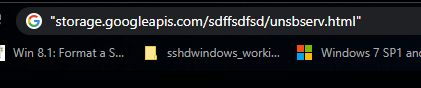
As expected, search returns only the URLScan page for this domain. Keep in mind though that sites such as ‘virustotal.com’ will often have results that do not appear on Google. They don’t allow Google search to index their results, so you would search directly on their site.
Now let’s try making a more useful Google search.
Can we try just the most unique part? If we get lucky that ‘sdffsdfsd’ string is reused elsewhere….
Slightly surprising results, just a couple Facebook pages that look pretty blank, and one or two other results which seem to be unrelated to each other or what we've seen so far.
*At this point I thought to myself, since the letters 'sdffsdfsd' turned up super generic results when it's a very specific search to make, why might that be. I realized then that looking at the keyboard, these numbers are very close together. So this probably reflects someone who can type randomly pressing keys with their left hand on the 'Home Row.'
The point though is that every time you're surprised by something, think about WHY it might be this way. It's OFTEN a super simple explanation like this one.
Next we’ll look and see what other pages with totally different URLs and IPs very closely match the domain we were examining with the possible phishing form.
(At the URLScan page for our original domain:
https://urlscan.io/result/78ac0178-2d8c-4276-b1fe-4b50f15a5365/)
Click “SIMILAR.”
Ah well, that’s a shame, but don't cry yet, push that "Vicks VapoRub infused" Puffs facial tissue right back into it's box!
We’ve got one more trick and it's a good one. This is the “SIMILAR” page for that URL with the form we've been looking at, but we can also check the same for the URLScan page of just the domain.
Keep in mind that this will be lower relevance because most of the time the suspicious URL (rather than the domain) is what we need to check for similar sites to. The front page could be the same as 999 other legitimate sites, then a malicious page appears on another page of the site. We'll check anyway though because I often get lucky and find other sites with similarly structured URLs anyway.
Here goes…
https://urlscan.io/result/a397e8e8-3947-443f-ad5d-bb0be34ea904/
So that page is for 1365abd[.]net itself. (don’t be tempted to remove the [ because it seems safe. In 3 months someone could come back to your work and click it, where it now has changed to deploy some "drive-by download" malware)
Looking at the ‘similar’ page now, we have plenty of results:
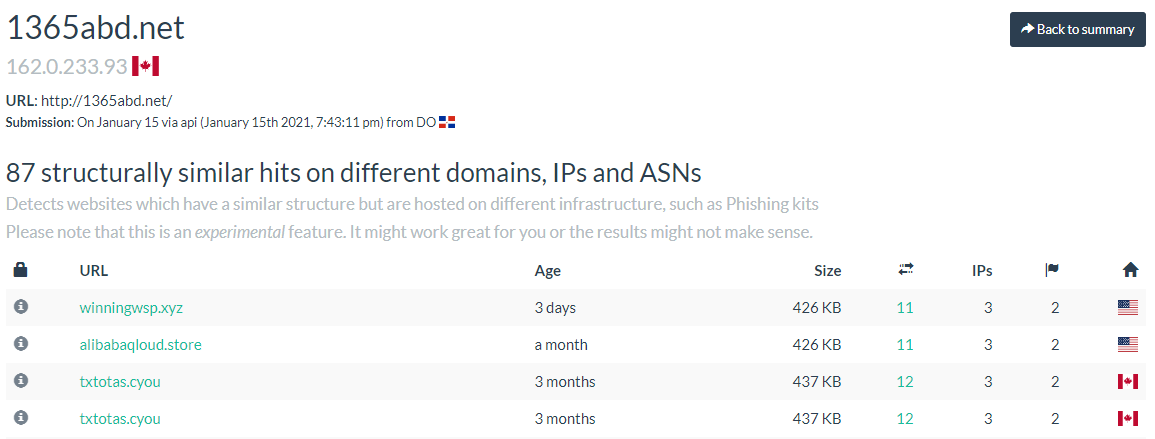
This is key. We don't know yet what URLScan considers ‘similar’ between these sites. So we have to tread carefully. Theorize, but assume nothing or you'll mislead yourself.
Quick wins here: find out if any of these match the same EXACT number in the “SIZE” field, and most likely same numbers in the fields next to it as well, but DEFINITELY the ‘SIZE’ field.
Let’s see…
Ah well, no luck. 437 for most of them.
But wait!
In another tab: Run a fresh scan for 1365abd[.]net.
In the same tab as the one you have open for the 'similar' pages, do another search for the domain (or from the beginning just back to URLScan.io, click ‘search.’)
This time you should see your recent scan, and you can compare the stats on the right for that one to the ones in the ‘similar’ section you have in your other tab.
1365abd[.]net has a load size of 438KB, then 11, 3, 2 (connections, IPs Contacted, Flags) as of today (15 JAN).
438, 11, 3, 2
What’s the next closest one in the “similar" results?
437, 12, 3, 2
That is the line for txtotas[.]cyou, but there are lots of others which are identical to it. So what does this do for us?
Our domain today has 1 more kb of data loaded than those other sites supposed to be ‘similar,’ to it.
Our domain’s front page load has 1 less connection being made, and the same number of IPs and flags.
We can’t tell just yet why there’s one less kb loaded however there’s a pretty good
chance that it did not load a 1kb resource that these other sites were loading
3 months ago.
This matters because they are close enough that we have a good chance to find out why the sites are similar!
What’s that missing http transaction between our domain’s front page and all these similar domains?
Here’s where are are now:
Our first domain...
https://urlscan.io/result/96f31bda-f21e-4a87-be28-f81185f89232/#transactions
And
The domain we think is being used exactly the same way.
https://urlscan.io/result/d94129ff-10eb-4751-bf79-4bf9a2104ffc/#transactions
(put the tabs side by side maybe in their own window together with no other tabs)
If you fully expand the window and scroll until you’re at the very top of the page on both tabs, you can switch from one to the other repeatedly and just watch what changes. This makes it easy to see if any of the requests that fit on the page have changed. You can do it for the second half of the page too, just make sure they both line up exactly when you scroll the sidebars in each tab.
Here's the HTTP request that changed:
fonts.gstatic.com/s/josefinslab/v11/lW-5wjwOK3Ps5GSJlNNkMalnqg6vBMjoPg.woff2
The only things that changed here are the fonts. Not very significant changes, but if these domains are being used exactly the same way, they seem to basically tell us that today’s version of the front page is more up to date than the versions in the ‘similar pages.’
Otherwise, these sites are running the same exactly template at the front page.
Not too farfetched/unusual.
Moment of Truth:
Do these other sites that are otherwise similar ALSO HAVE THE SAME URLs being looked up in URLScan? If so, we’ve got em.
Very likely this would be our smoking gun showing us that the form is phishing activity.
Aaand there it is…..nailed it!
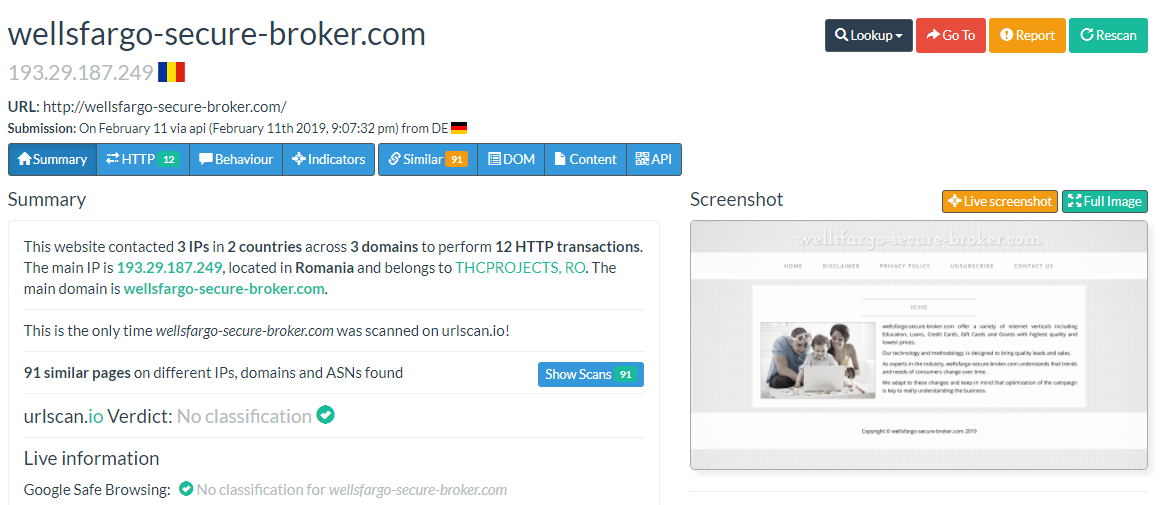
https://urlscan.io/result/cafd937b-4ca2-45cf-ac45-db3bd24d311e/
The final piece of evidence we needed here is this:
If you click ‘Show Scans’ on the ‘txtotas’ page, you’ll see a very familiar URL scheme:
The same is found at “wellsfargo-secure-broker[.]com” from the similar sites list.
If that’s not a phishing domain I’m Burt Reynolds, and I just don’t have the chest hair to pull that one off.
So to summarize, and make sure that we trace our conclusion from start to finish so that we know we haven’t run off the rails somewhere chasing indicators that might not even be related…
The original domain uses this ‘out of the box’ website template
The ‘wellsfargo’ phishing domain uses the exact same template
Many, many other domains match both of these just about exactly.
The urls used in our original domain are identical in format to each of these others.
Now we know that this is at the very least an attacker operating phishing sites
using the same method at each one.
I hope this has been helpful for you! If so please pass it around so others can learn too, and please come back next time for my 2nd post in the Security Analyst Skills series. If you have any questions, mistakes, errors, feedback, etc...
PLEASE let me know either in comments here or via Twitter at @NerdShinobe.
Nice Explanation. Thanks
ReplyDeleteYou're very welcome Sai, I'm glad to hear it was useful to you! Be sure to come back in about a week for the next post.
Delete